Q&A 23 How do you apply cross-validation strategies to evaluate model reliability?
23.1 Explanation
Cross-validation (CV) is critical for evaluating how well a machine learning model generalizes to unseen data. It reduces the risk of overfitting by testing the model on multiple train/test splits.
Common CV strategies: - k-Fold: Split into k subsets, rotate test set - Repeated k-Fold: More robust by repeating k-fold several times - Stratified k-Fold: Ensures balanced class distribution in folds
This Q&A shows how to apply CV in Python and R using common microbiome classifiers.
23.2 Python Code
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
# Load and prepare data
otu_df = pd.read_csv("data/otu_table_filtered.tsv", sep="\t", index_col=0).T
meta_df = pd.read_csv("data/sample_metadata.tsv", sep="\t")
data = pd.merge(otu_df, meta_df, left_index=True, right_on="sample_id")
X = data[otu_df.columns]
y = data["group"].map({"Control": 0, "Treatment": 1})
# Define CV strategy
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# Evaluate Random Forest using cross-validation
model = RandomForestClassifier(random_state=42)
scores = cross_val_score(model, X, y, cv=cv, scoring="accuracy")
print("Cross-Validation Accuracy Scores:", scores)
print("Mean Accuracy:", scores.mean())23.3 R Code (caret with repeated k-fold CV)
library(tidyverse)
library(caret)
otu_df <- read.delim("data/otu_table_filtered.tsv", row.names = 1)
meta_df <- read.delim("data/sample_metadata.tsv")
otu_df <- otu_df[, meta_df$sample_id]
otu_df <- t(otu_df)
data <- cbind(as.data.frame(otu_df), group = as.factor(meta_df$group))
# Define CV control
ctrl <- trainControl(method = "repeatedcv", number = 5, repeats = 3)
# Train with CV
set.seed(42)
cv_model <- train(group ~ ., data = data, method = "rf", trControl = ctrl)
# Results
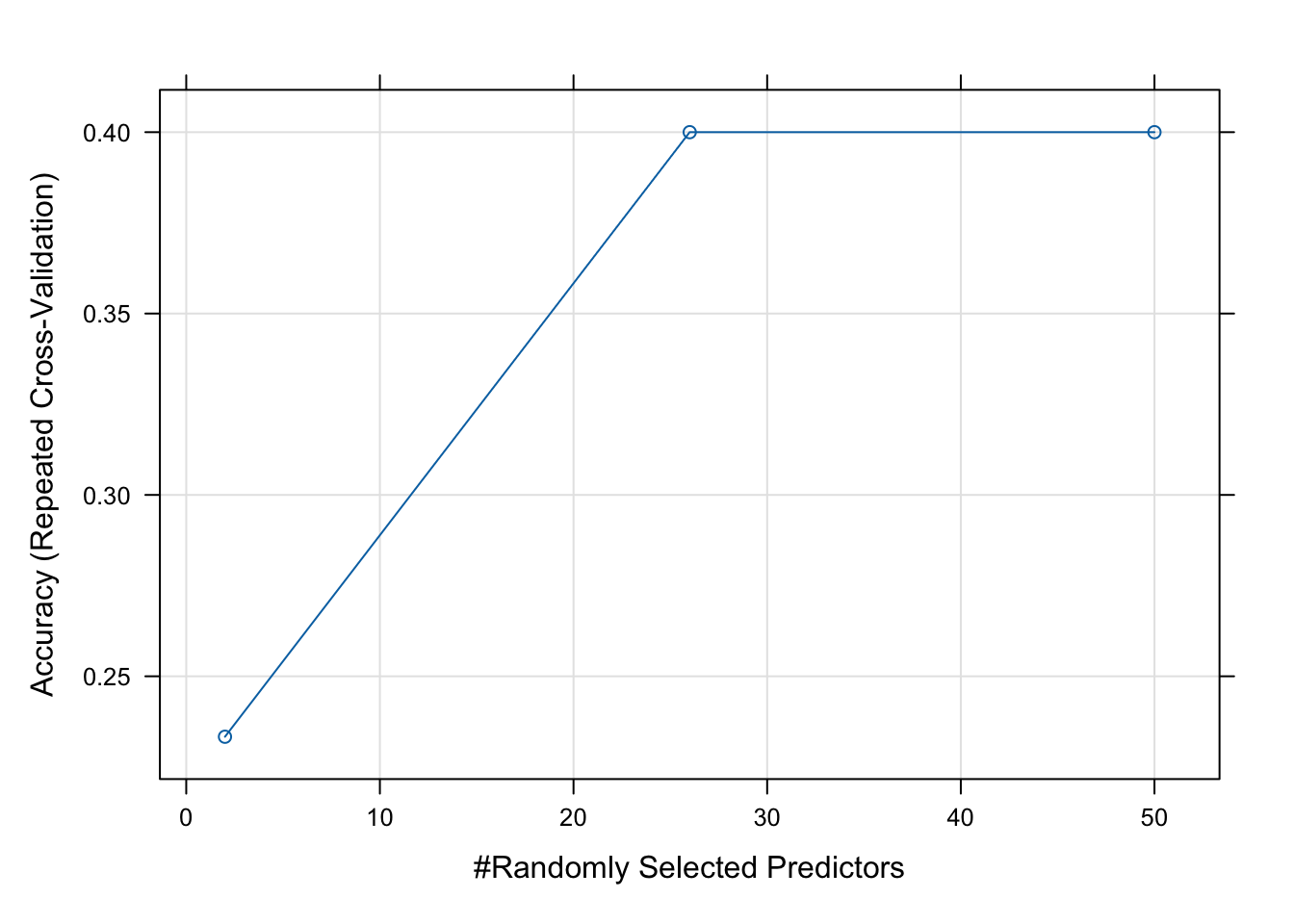
print(cv_model)Random Forest
10 samples
50 predictors
2 classes: 'Control', 'Treatment'
No pre-processing
Resampling: Cross-Validated (5 fold, repeated 3 times)
Summary of sample sizes: 8, 8, 8, 8, 8, 8, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.2333333 -0.5333333
26 0.4000000 -0.2000000
50 0.4000000 -0.2000000
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 26.